简介
Pod存在生命周期,有销毁,有重建,无法提供一个固定的访问接口给客户端。并且为了同类的Pod都能够实现工作负载的价值,由此Service资源出现了,可以为一类Pod资源对象提供一个固定的访问接口和负载均衡。
Service和Pod对象的IP地址,一个是虚拟地址,一个是Pod IP地址,都仅仅在集群内部可以进行访问,无法接入集群外部流量。而为了解决该类问题的办法可以是在单一的节点上做端口暴露(hostPort)以及让Pod资源共享工作节点的网络名称空间(hostNetwork)以外,还可以使用NodePort或者是LoadBalancer类型的Service资源,或者是有7层负载均衡能力的Ingress资源。
Service是Kubernetes的核心资源类型之一,Service资源基于标签选择器将一组Pod定义成一个逻辑组合,并通过自己的IP地址和端口调度代理请求到组内的Pod对象,如下图所示,它向客户端隐藏了真是的,处理用户请求的Pod资源,使得从客户端上看,就像是由Service直接处理并响应一样,是不是很像负载均衡器呢!
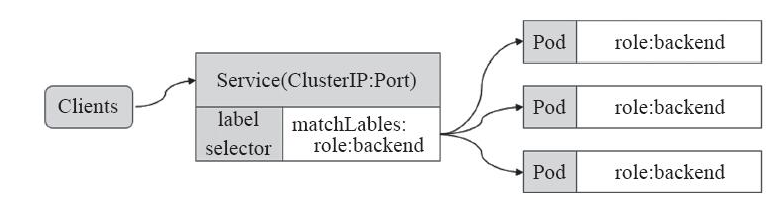
Service对象的IP地址也称为Cluster IP,它位于为Kubernetes集群配置指定专用的IP地址范围之内,是一种虚拟的IP地址,它在Service对象创建之后保持不变,并且能够被同一集群中的Pod资源所访问。Service端口用于接受客户端请求,并将请求转发至后端的Pod应用的相应端口,这样的代理机制,也称为端口代理,它是基于TCP/IP 协议栈的传输层。
Service能够提供负载均衡的能力,但是只提供 4 层负载均衡能力,而没有 7 层功能,但有时我们可能需要更多的匹配规则来转发请求,这时就需要使用Ingress了。
定义
一个Service在 Kubernetes 中是一个 REST 对象,和Pod类似。 像所有的 REST 对象一样, Service 定义可以基于 POST 方式,请求 API server 创建新的实例。
例如,假定有一组 Pod,它们对外暴露了 9376 端口,同时还被打上 app=MyApp 标签。
1 | apiVersion: v1 |
上述YAML最重要的4个字段为:
1 | apiVersion: |
上述配置创建一个名称为 “my-service” 的 Service 对象,在集群内部去访问这个80端口的流量,它会将请求代理到使用 TCP 端口 9376,并且具有标签 "app=MyApp" 的 Pod 上。
Kubernetes 为该服务分配一个 IP 地址(有时称为 “集群IP” ),该 IP 地址由服务代理使用。服务选择器的控制器不断扫描与其选择器匹配的 Pod,然后将所有更新发布到也称为 “my-service” 的Endpoint对象。
需要注意的是, Service 能够将一个接收 port 映射到任意的 targetPort。 默认情况下,targetPort 将被设置为与 port 字段相同的值。
port和nodePort都是service的端口,前者暴露给k8s集群内部服务访问,后者暴露给k8s集群外部流量访问。从上两个端口过来的数据都需要经过反向代理kube-proxy,流入后端pod的targetPort上,最后到达pod内的容器。
如果需要给指定的pod、deployment等暴露端口,可以直接运行命令:kubectl expose pod nginx --port=80 --target-port=9379 --type ClusterIP --name=my-service -o yaml --dry-run,效果跟上述yaml是类似的。
代理模式的分类
在Kubernetes集群中,每个Node运行一个kube-proxy进程。kube-proxy负责为Service实现一种VIP(虚拟IP)的形式,而不是ExternalName的形式。在Kubernetes v1.0版本中,代理完全在userspace。在Kubernetes v1.1版本中,新增了iptables代理,但并不是默认的运行模式。从Kubernetes v1.2起,默认就是iptables代理。在Kubernetes v1.8.0-beta.0中,添加了ipvs代理。在Kubernetes v1.0版本中,Service是“4层”(TCP/UDP over IP)概念。在Kubernetes v1.1版本中,新增了Ingress API(beta版),用来表示“7层”(HTTP)服务。
kube-proxy 这个组件始终监视着apiserver中有关service的变动信息,获取任何一个与service资源相关的变动状态,通过watch监视,一旦有service资源相关的变动和创建,kube-proxy都要转换为当前节点上的能够实现资源调度规则(例如:iptables、ipvs)。
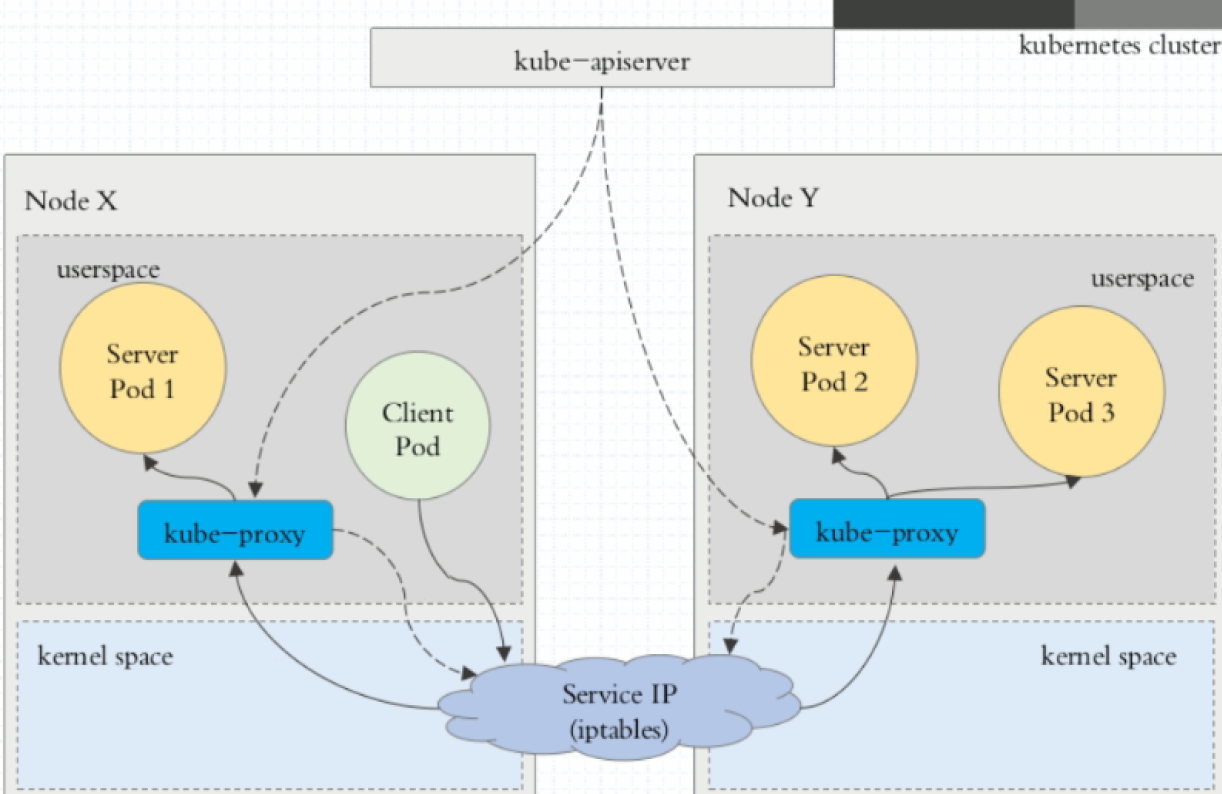
userspace代理模式
这种模式,当客户端Pod请求内核空间的service iptables后,把请求转到给用户空间监听的kube-proxy 的端口,由kube-proxy来处理后,再由kube-proxy将请求转给内核空间的 service ip,再由service iptalbes根据请求转给各节点中的的service pod。
由此可见这个模式有很大的问题,由客户端请求先进入内核空间的,又进去用户空间访问kube-proxy,由kube-proxy封装完成后再进去内核空间的iptables,再根据iptables的规则分发给各节点的用户空间的pod。这样流量从用户空间进出内核带来的性能损耗是不可接受的。在Kubernetes 1.1版本之前,userspace是默认的代理模型。
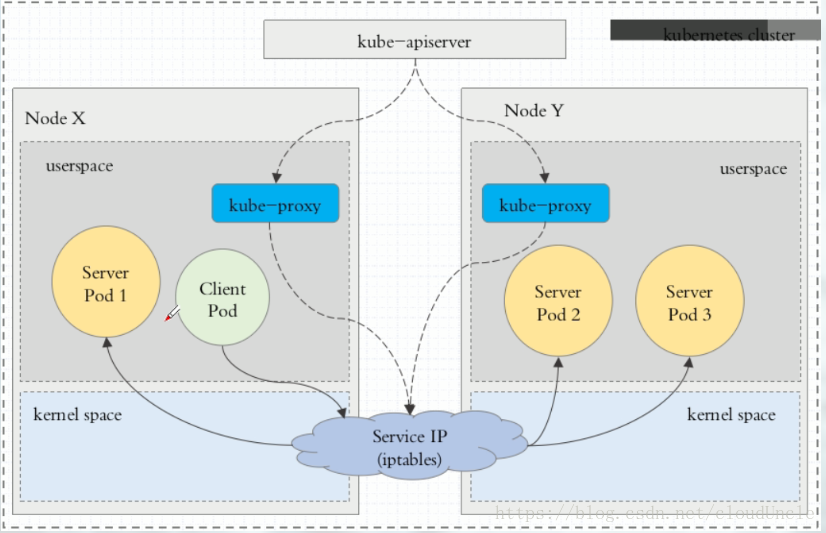
iptables代理模式
这种模式下,Client Pod直接请求本地内核service ip,根据iptables规则直接将请求转发到各pod上,因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存在上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折扣。
ipvs代理模式
这种模式下,Client Pod请求到达内核空间时,根据ipvs规则直接分发到各Pod上。kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应的创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter的hook功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快的重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
1 | rr:轮询调度 |
注意: ipvs代理模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式。
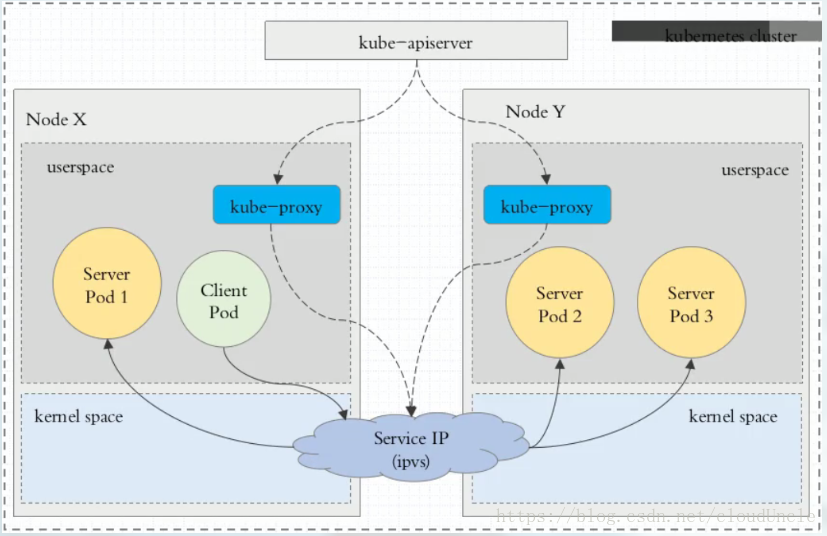
如果某一个服务后端pod发生变化,标签选择器适应的pod又多一个,适应的信息会立即反映到apiserver上,而kube-proxy一定可以watch到etcd中的信息变化,而将它立即转为ipvs或iptables规则中,这一切都是动态和实时的,删除一个pod也是同样的原理。
Service的类型
有以下四种类型:
ClusterIp:默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP。clusterIP主要在每个node节点使用iptables,将发向clusterIP对应端口的数据,转发到kube-proxy中。然后kube-proxy自己内部实现有负载均衡的方法,并可以查询到这个service下对应pod的地址和端口,进而把数据转发给对应的pod的地址和端口。
NodePort:在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过
<NodeIP>: NodePort来访问该服务,注意,每台Node都会开放此端口。nodePort的原理在于在node上开了一个端口,将向该端口的流量导入到kube-proxy,然后由kube-proxy进一步到给对应的pod。LoadBalancer:在NodePort的基础上,借助cloud provider创建一个外部负载均衡器,并将请求转发到
<NodeIP>: NodePort。是需要云厂商的支持。ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有kubernetes 1.7或更高版本的kube-dns才支持。
ClusterIp
创建myapp-deploy.yaml文件:
1 | apiVersion: apps/v1 |
创建之后,查看deploy以及pods:
1 | [root@master ~]# kubectl get deployments.apps myapp-deploy |
再查看service:
1 | [root@master ~]# kubectl get svc myapp |
注意看CLUSTER-IP与POD的IP是不在同一段里面的。svc的IP是虚拟的,所以是无法ping通的。而ENDPOINTS对应的三个IP就是pod的IP。
service只要创建完,就会在dns中添加一个资源记录进行解析,添加完成即可进行解析。资源记录的格式为:SVC_NAME.NameSpace_NAME.DOMAIN.LTD.,默认的集群service 的A记录:svc.cluster.local.,而默认的是namespaces为default,所以这个SVC的DNS名称为:myapp.default.svc.cluster.local。
进入busybox,我们来验证下:
1 | [root@master ~]# kubectl run dnstest --rm --image=busybox:1.28 -it --restart=Never -- /bin/sh |
查看iptables规则:
1 | [root@master ~]# iptables -t nat -nvL |
- 在PREROUTING链中会先匹配到KUBE-SERVICES这个Chain;
- 所有destination IP为10.111.154.233的包都转到KUBE-SVC-JOCJVTCKLKOLHFVR这个Chain;
- 在KUBE-SVC-JOCJVTCKLKOLHFVR的chain里面,可以看到是平均会运行到三个链里面
- 以KUBE-SEP-EZJKRTZXRZURMDDV为例,这条Chain使用了DNAT规则将流量转发到10.32.0.11:80这个地址上,这就是一个POD的IP地址。
k8s以这样的一种机制实现了负载均衡。
NodePort
对于这种类型,Kubernetes将会在每个Node上打开一个端口并且每个Node的端口都是一样的,通过<NodeIP>:NodePort的方式Kubernetes集群外部的程序可以访问Service。将上文里面的Service的type改为NodePort类型。
1 | [root@master ~]# k apply -f 1.yaml |
可以看到kubernetes已经随机给我们分配了一个NodePort端口了。
ExternalName
这种类型的Service通过返回CNAME和它的值,可以将服务映射到externalName字段的内容(例如:foo.bar.example. com)。ExternalName Service是Service的特例,它没有selector,也没有定义任何的端口和Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
1 | kind: Service |
当查询主机my-service.prod.svc.cluster.local(SVC_NAME.NAMESPACE.svc.cluster.local)时,集群的DNS服务将返回一个值my.database.example.com的CNAME记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在DNS层,而且不会进行代理或转发。
Headless Service
有时不需要或不想要负载均衡,以及单独的Service IP。遇到这种情况,可以通过指定Cluster IP(spec.clusterIP)的值为“None”来创建Headless Service。
这个选项允许开发人员自由的寻找他们自己的方式,从而降低与Kubernetes系统的耦合性。应用仍然可以使用一种自注册的模式和适配器,对其他需要发现机制的系统能够很容易的基于这个API来构建。
对这类Service并不会分配Cluster IP,kube-proxy不会处理它们,而且平台也不会为它们进行负载均衡和路由。DNS如何实现自动配置,依赖于Service时候定义了selector。
编写headless service配置清单:
1 | apiVersion: v1 |
查看svc,发现CLUSTER-IP是空:
1 | [root@master ~]# k apply -f 1.yaml |
这有什么用呢?我们来解析一下:
1 | [root@master ~]# kubectl apply -f 1.yaml |
从以上的演示可以看到对比普通的service和headless service,headless service做dns解析是直接解析到pod的,而servcie是解析到ClusterIP的。这有什么用呢?这在statefulset是很有用处的。