zookeeper
简介
ZooKeeper是一个开源的分布式应用程序协调服务,是Google的Chubby一个开源的实现。ZooKeeper为分布式应用提供一致性服务,提供的功能包括:分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)、分布式锁(Distributed Lock)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。
ZooKeeper本身可以以单机模式安装运行,不过它的长处在于通过分布式ZooKeeper集群(一个Leader,多个Follower),基于一定的策略来保证ZooKeeper集群的稳定性和可用性,从而实现分布式应用的可靠性。
ZooKeeper主要有领导者(Leader)、跟随者(Follower)和观察者(Observer)三种角色。
| 角色 | 说明 |
|---|---|
| 领导者(Leader) | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
| 跟随者(Follower) | 为客户端提供读服务,如果是写服务则转发给Leader。在选举过程中参与投票。 |
| 观察者(Observer) | 为客户端提供读服务器,如果是写服务则转发给Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于zookeeper3.3系列新增的角色。 |
部署
根据官方说明,如果使用java 1.8的版本的话,需要使用u211以上的版本,但实测u161也是可以使用的。
1 | yum install java-1.8.0-openjdk -y |
zoo.cfg的配置:
1 | tickTime=2000 |
tickTime:心跳基本时间单位,毫秒级,ZK基本上所有的时间都是这个时间的整数倍。
initLimit:tickTime的个数,表示在leader选举结束后,followers与leader同步需要的时间,如果followers比较多或者说leader的数据灰常多时,同步时间相应可能会增加,那么这个值也需要相应增加。当然,这个值也是follower和observer在开始同步leader的数据时的最大等待时间(setSoTimeout)
- syncLimit:tickTime的个数,这时间容易和上面的时间混淆,它也表示follower和observer与leader交互时的最大等待时间,只不过是在与leader同步完毕之后,进入正常请求转发或ping等消息交互时的超时时间
- dataDir:内存数据库快照存放地址,如果没有指定事务日志存放地址(dataLogDir),默认也是存放在这个路径下,建议两个地址分开存放到不同的设备上。
- clientPort:配置ZK监听客户端连接的端口
- dataLogDir:将事务日志存储在该路径下,比较重要,这个日志存储的设备效率会影响ZK的写吞吐量。
- server.serverid=host:tickpot:electionport
- server:固定写法
- serverid:每个服务器的指定ID(必须处于1-255之间,必须每一台机器不能重复)
- host:主机名,直接用IP更容易识别
- tickpot:心跳通信端口
- electionport:选举端口
- 这里的serverid要写入到
/usr/local/zookeeper-3.6.2/data/myid下,注意每台机器都不一样。
由于/usr/local/zookeeper-3.6.2/bin目录下面是zookeeper的运行命令所在位置,可以将他加入到系统变量中去。
1 | [root@iloqg8n3yb9mje data]# cat /etc/profile.d/zookeeper.sh |
服务启动
启动服务,使用zkServer.sh start,但我们可以使用以下systemd来接管。
1 | $ systemctl cat zookeeper |
集群状态查看
使用zkServer.sh status查看集群状态;需要等三台全部启动之后才会显示MODE的状态,如果只启动一台的话,就会显示Error contacting service. It is probably not running.;
1 | [root@iabnt3f4lvt0va data]# zkServer.sh start |
如果三台都启动了,但没有显示mode,可以查看/usr/local/zookeeper-3.6.2/logs下面的日志进行排查。
zookeeper的操作,运行/usr/local/zookeeper-3.6.2/bin/zkCli.sh -server 192.168.0.14:
1 | [zk: localhost:2181(CONNECTED) 0] ls / |
zxid:一个事务编号,zookeeper集群内部的所有事务,都有一个全局的唯一的顺序的编号,由两部分组成: 就是一个 64位的长整型 long:
- 高32位: 用来标识leader关系是否改变,如 0x2
- 低32位: 用来做当前这个leader领导期间的全局的递增的事务编号,如 00000007
get -s可以使用查看zxid的详细数据。
| 状态属性 | 说明 |
|---|---|
| cZxid | 数据节点创建时的事务ID |
| ctime | 数据节点创建时的时间 |
| mZxid | 数据节点最后一次更新时的事务ID |
| mtime | 数据节点最后一次更新时的时间 |
| pZxid | 数据节点的子节点列表最后一次被修改(是子节点列表变更,而不是子节点内容变更)时的事务ID |
| cversion | 子节点的版本号 |
| dataVersion | 数据节点的版本号 |
| aclVersion | 数据节点的ACL版本号 |
| ephemeralOwner | 如果节点是临时节点,则表示创建该节点的会话的SessionID;如果节点是持久节点,则该属性值为0 |
| dataLength | 数据内容的长度 |
| numChildren | 数据节点当前的子节点个数 |
https://zookeeper.apache.org/doc/current/zookeeperStarted.html
kafka
Kafka是一个开源的分布式消息引擎/消息中间件,同时Kafka也是一个流处理平台。Kakfa支持以发布/订阅的方式在应用间传递消息,同时并基于消息功能添加了Kafka Connect、Kafka Streams以支持连接其他系统的数据等)
Kafka最核心的最成熟的还是他的消息引擎,所以Kafka大部分应用场景还是用来作为消息队列削峰平谷。另外,Kafka也是目前性能最好的消息中间件。
在Kafka集群(Cluster)中,一个Kafka节点就是一个Broker,消息由Topic来承载,可以存储在1个或多个Partition中。发布消息的应用为Producer、消费消息的应用为Consumer,多个Consumer可以促成Consumer Group共同消费一个Topic中的消息。
| 概念/对象 | 简单说明 |
|---|---|
| Broker | Kafka节点 |
| Topic | 主题,用来承载消息,可以理解为数据库里面的表 |
| Partition | 分区,用于主题分片存储,可以理解为多机器存储,比如说设置分区为3,kafka会根据一定的算法动态存储到不同的broker上 |
| Producer | 生产者,向主题发布消息的应用 |
| Consumer | 消费者,从主题订阅消息的应用 |
| Consumer Group | 消费者组,由多个消费者组成 |
安装
下载
1 | cd /usr/local/src |
修改配置
1 | $ cat server.properties |grep -v '^#' |grep -v '^$' |
启动服务
命令运行之前,最好是把软件包配置到其他机器上再来运行。
运行命令kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties就可以运行命令了。第一次运行时,可能会报错,可以将daemon先去掉,这样就可以输出报错日志了。
另外可以使用systemctl来管理服务:
1 | # 修改环境变量 |
配置性能优化
消息大小相关参数
以下参数优化来源于 彻底搞懂 Kafka 消息大小相关参数设置的规则
- max.request.size:producer端发送消息的最大的大小
- batch.size:producer:非常重要的参数,收集到一批消息再发送到 broker,比每条消息都请求一次 broker,性能会有显著的提高,但 batch.size 设置得非常大又会给机器内存带来极大的压力,因此需要在项目中合理地增减 batch.size 值,才能提高 producer 的吞吐量。
message.max.bytes:Broker 端对 Producer 发送过来的消息也有一定的大小限制,默认值为1M- max.message.bytes:它只针对某个主题生效,可动态配置,可覆盖全局的 message.max.bytes,好处就是可以针对不同主题去设置 Broker 接收消息的大小,而且不用重启 Broker。
- fetch.max.byte:这个参数决定消费者单次从 Broker 获取消息的最大字节数
replica.fetch.max.bytes:限制副本拉取分区中消息的大小,尽可能要设置为比message.max.bytes更大,也可以设置为一样大的值socket.request.max.bytes:socket请求的最大数值,为了防止serverOOM,
message.max.bytes一定要小于socket.request.max.bytes
从broker的优化角度,message.max.bytes、replica.fetch.max.bytes、socket.request.max.bytes这三个值必须调大。
内部topic优化
我们知道老版本的消费位移信息是存储的zookeeper 中的, 但是zookeeper 并不适合频繁的写入查询操作,所以在新版本的中消费位移信息存放在了__consumer_offsets内置topic中,所以这个topic很重要,但默认配置下,一个分区只有一个副本,当该副本所在的broker宕机,consumer_offsets只有一份副本,该分区宕机。使用该分区存储消费分组offset位置的消费者均会收到影响,offset无法提交,从而导致生产者可以发送消息但消费者不可用。所以需要设置该字段的值大于1。
1 | offsets.topic.replication.factor=3 |
其他参数
1 | # 默认值为False。默认情况下leader不能从非ISR的副本列表里选择;在异常情况下,比如ISR内的副本都不可用了,此时如果该字段设置为False,服务会直接挂掉; |
相关操作
创建Topic
随便找一台机器创建测试Tpoic:test,这里我们指定了3个副本、1个分区:
1 | [root@4n1eq6wnfvdwvj logs]# kafka-topics.sh --create --bootstrap-server 192.168.0.14:9092 --replication-factor 3 --partitions 1 --topic test |
生产数据
运行命令之后,输入内容就是一条消息:
1 | [root@4n1eq6wnfvdwvj logs]# kafka-console-producer.sh --broker-list 192.168.0.13:9092 --topic test |
消费数据
1 | # 从头开始消费 |
查看leader
1 | # 创建一个名为cpu的topic,分为4个分区,3副本 |
Leader会跟踪与其保持同步的Replica列表,该列表称为ISR(即in-sync Replica)。
kafka in zookeeper
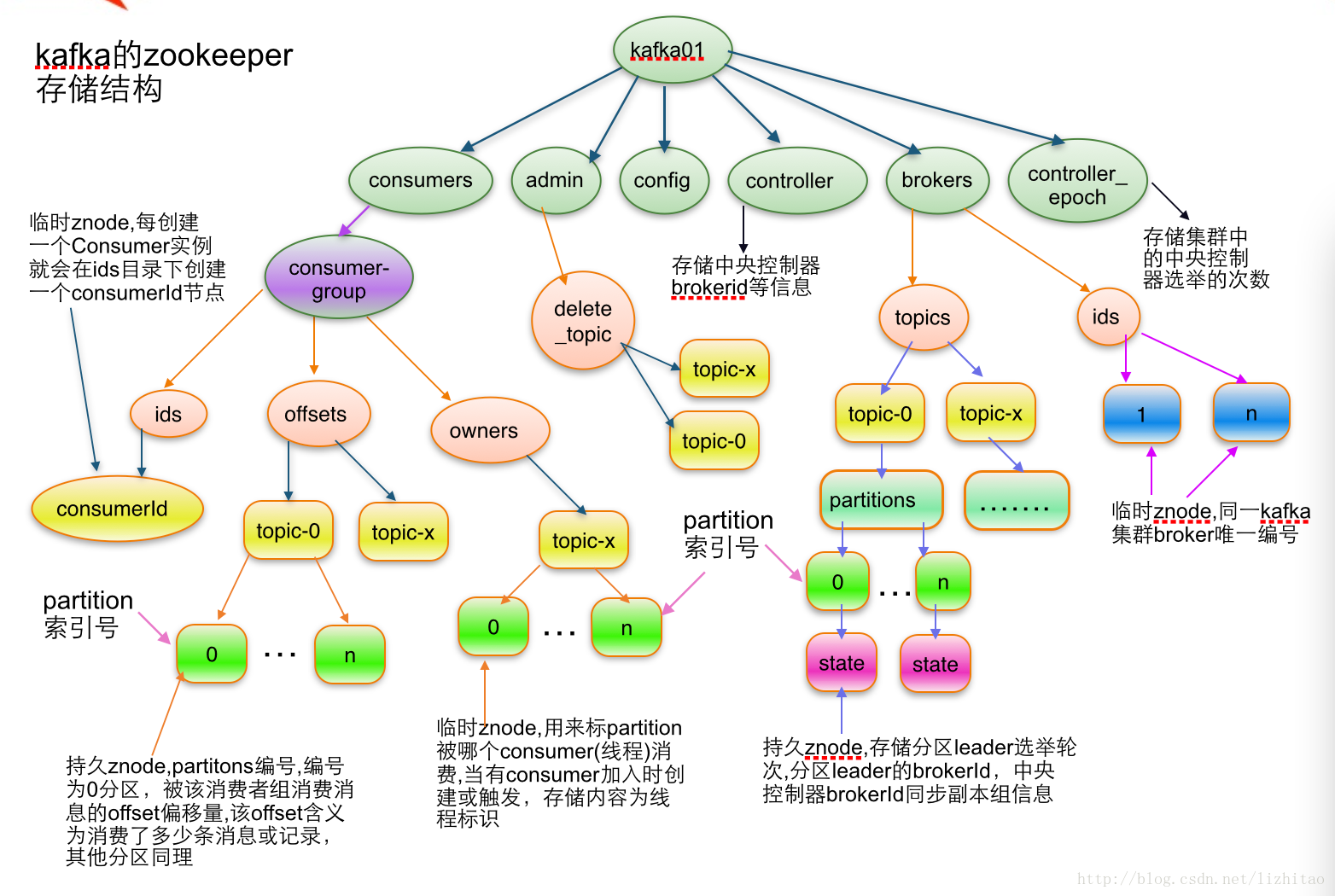
查看id和topics
/brokers/topics/[topic] :存储某个topic的partitions所有分配信息
运行zkCli.sh
1 | [zk: localhost:2181(CONNECTED) 0] ls /brokers/ids |
partition状态信息
/brokers/topics/[topic]/partitions/[0…N] 其中[0..N]表示partition索引号
/brokers/topics/[topic]/partitions/[partitionId]/state
1 | [zk: localhost:2181(CONNECTED) 5] ls /brokers/topics/cpu/partitions |
最后一条表示partitions 0这个分区的leader在14这台机器上面;controller_epoch表示kafka集群中的中央控制器选举次数;leader_epoch表示 该partition leader选举次数。
controller信息
- controller_epoch:此值为一个数字,kafka集群中第一个broker第一次启动时为1,以后只要集群中center controller中央控制器所在broker变更或挂掉,就会重新选举新的center controller,每次center controller变更controller_epoch值就会 + 1;
- controller:存储center controller中央控制器所在kafka broker的信息
1 | [zk: localhost:2181(CONNECTED) 8] get /controller_epoch |