POD资源限制
简介
容器运行过程中需要分配所需的资源,如何与cggroup联动配合呢?答案是通过定义resource来实现资源的分配,资源的分配单位主要是cpu和memory,资源的定义分两种:requests和limits,requests表示请求资源,主要用于初始kubernetes调度pod时的依据,表示必须满足的分配资源;limits表示资源的限制,即pod不能超过limits定义的限制大小,超过则通过cggroup限制,pod中定义资源可以通过下面四个字段定义:
- spec.container[].resources.requests.cpu 请求cpu资源的大小,如
0.1个cpu和100m表示分配1/10个cpu; - spec.container[].resources.requests.memory 请求内存大小,单位可用M,Mi,G,Gi表示;
- spec.container[].resources.limits.cpu 限制cpu的大小,不能超过阀值,cggroup中限制的值;
- spec.container[].resources.limits.memory 限制内存的大小,不能超过阀值,超过会发生OOM;
如下以定义nginx-demo为例,容器请求cpu资源为250m,限制为500m,请求内存资源为128Mi,限制内存资源为256Mi,当然也可以定义多个容器的资源,多个容器相加就是pod的资源总资源
1 | apiVersion: v1 |
创建并查看pod资源的分配详情。
1 | [root@master ~]# kubectl apply -f 1.yaml |
Pod的资源如何分配呢?毫无疑问是从node上分配的,当我们创建一个pod的时候如果设置了requests,kubernetes的调度器kube-scheduler会执行两个调度过程:filter过滤和weight称重,kube-scheduler会根据请求的资源过滤,把符合条件的node筛选出来,然后再进行排序,把最满足运行pod的node筛选出来,然后再特定的node上运行pod。如下是node1的情况:
1 | [root@master ~]# kubectl describe nodes node1 |
资源限制的原理
Pod的定义的资源requests和limits作用于kubernetes的调度器kube-sheduler上,实际上cpu和内存定义的资源会应用在container上,通过容器上的cggroup实现资源的隔离作用,接下来我们介绍下资源分配的原理。
spec.containers[].resources.requests.cpu:作用在CpuShares,表示分配cpu 的权重,争抢时的分配比例spec.containers[].resources.requests.memory:主要用于kube-scheduler调度器,对容器没有设置意义spec.containers[].resources.limits.cpu:作用CpuQuota和CpuPeriod,单位为微秒,计算方法为:CpuQuota/CpuPeriod,表示最大cpu最大可使用的百分比,如500m表示允许使用1个cpu中的50%资源spec.containers[].resources.limits.memory:作用在Memory,表示容器最大可用内存大小,超过则会OOM
以上面定义的nginx-demo为例,研究下pod中定义的requests和limits应用在docker生效的参数:
- 在node1上面运行如下命令。默认会有两个pod:一个通过pause镜像创建,另外一个通过应用镜像创建。
1 | [root@node1 ~]# docker ps |grep nginx-demo |
- 查看docker容器详情信息
1 | [root@node1 ~]# docker inspect 1f99d75fb3a9 |egrep 'CpuShares|Memory"|CpuPeriod|CpuQuota' |
- 容器计算资源管理:https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
- pod内存资源管理:https://kubernetes.io/docs/tasks/configure-pod-container/assign-memory-resource/
- pod cpu资源管理:https://kubernetes.io/docs/tasks/configure-pod-container/assign-cpu-resource/
- kubernetes系列教程(六)kubernetes资源管理和服务质量:https://cloud.tencent.com/developer/article/1515066
POD调度
pod调度概述
kubernets是容器编排引擎,其中最主要的一个功能是容器的调度,通过kube-scheduler实现容器的完全自动化调度,调度周期分为:调度周期Scheduling Cycle和绑定周期Binding Cycle,其中调度周期细分为过滤filter和weight称重,按照指定的调度策略将满足运行pod节点的node赛选出来,然后进行排序;绑定周期是经过kube-scheduler调度优选的pod后,由特定的node节点watch然后通过kubelet运行。
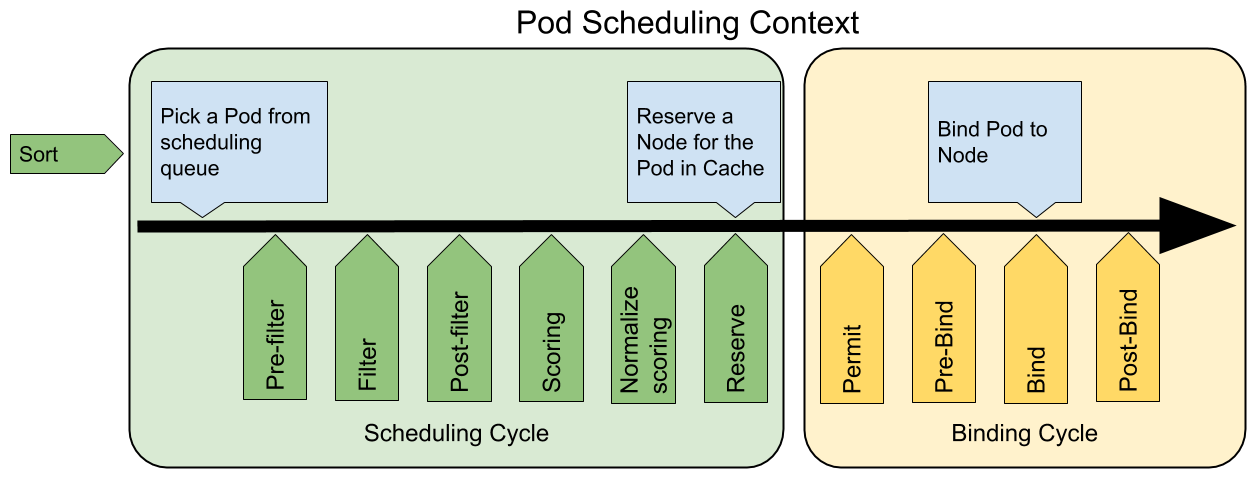
过滤阶段包含预选Predicate和scoring排序,预选是筛选满足条件的node,排序是最满足条件的node打分并排序。
指定nodeName调度
nodeName是PodSpec中的一个字段,可以通过pod.spec.nodeName指定将pod调度到某个具体的node节点上,该字段比较特殊一般都为空,如果有设置nodeName字段,kube-scheduler会直接跳过调度,在特定节点上通过kubelet启动pod。通过nodeName调度并非是集群的智能调度,通过指定调度的方式可能会存在资源不均匀的情况,建议设置Guaranteed的Qos,防止资源不均时候Pod被驱逐evince。
1 | apiVersion: v1 |
nodeSelector节点选择
nodeSelector是PodSpec中的一个字段,nodeSelector是最简单实现将pod运行在特定node节点的实现方式,其通过指定key和value键值对的方式实现,需要node设置上匹配的Labels,节点调度的时候指定上特定的labels即可。
可以使用 kubectl label nodes node1 disktype=ssd 增加一个label。
1 | apiVersion: v1 |
这样就会调度到node1上面了。
系统默认预先定义有多种内置的labels,这些labels可以标识node的属性,如arch架构,操作系统类型,主机名等
- beta.kubernetes.io/arch=amd64
- beta.kubernetes.io/os=linux
- kubernetes.io/arch=amd64
- kubernetes.io/hostname=node-3
- kubernetes.io/os=linux
Node affinity节点亲和
affinity/anti-affinity和nodeSelector功能相类似,相比于nodeSelector,affinity的功能更加丰富,未来会取代nodeSelector。node亲和包括2种,affinity增加了如下的一些功能增强:
- 表达式更加丰富,匹配方式支持多样,如
In,NotIn, Exists, DoesNotExist. Gt, and Lt; - 通过
requiredDuringSchedulingIgnoredDuringExecution来设置,为硬性选择指标,必须满足这个条件;而preference则是优选选择条件,通过preferredDuringSchedulingIgnoredDuringExecution指定,表示的意思是最好是调度到哪里去。 - affinity提供两种级别的亲和和反亲和:基于node的node affinity和基于pod的inter-pod affinity/anti-affinity,node affinity是通过node上的labels来实现亲和力的调度,而pod affinity则是通过pod上的labels实现亲和力的调度,两者作用的范围有所不同。
1 | apiVersion: v1 |
上述YAML表示 ,POD必须调度到kubernetes.io/e2e-az-name这个kEY为e2e-az1或者是e2e-az2的上面,不然就不满足需求。如果another-node-label-key这个KEY和value有匹配上的node,就优先调度到这个node。如果没有这个KEY,也没有关系。
如果你同时指定了 nodeSelector 和 nodeAffinity,两者必须都要满足,才能将 pod 调度到候选节点上。preferredDuringSchedulingIgnoredDuringExecution里面的 weight 取值范围为1~100。值越高,为最优选择。
https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
pod affinity/anti-affinity
pod间的亲和与反亲和使你可以基于已经在节点上运行的pod的标签来约束 pod 可以调度到的节点,而不是基于节点上的标签。规则为:如果 X 节点上已经运行了一个或多个满足规则 Y 的pod,则这个 pod 应该(或者在非亲和的情况下不应该)运行在 X 节点。
和 Node不同,由于 Pod 都是有命名空间的,所以基于 Pod 标签的标签选择器(Label Selector)必须指定命名空间。可以通过 namespaces(与 labelSelector 和 topologyKey 同一级) 指定,默认情况下为拥有亲和性(或反亲和性)的 Pod 所属的命名空间,如果定义了 namespaces 但值是空的,则表示使用 all 命名空间。
topology 就是 拓扑 的意思,这里指的是一个 拓扑域,是指一个范围的概念,比如一个 Node、一个机柜、一个机房或者是一个地区(如杭州、上海)等,实际上对应的还是 Node 上的标签。这里的 topologyKey 对应的是 Node 上的标签的 Key(没有Value),可以看出,其实 topologyKey 就是用于筛选 Node 的。通过这种方式,我们就可以将各个 Pod 进行跨集群、跨机房、跨地区的调度了。
1 | apiVersion: v1 |
这里 Pod 的亲和性规则是:这个 Pod 要调度到的 Node 必须有一个标签为 security: S1 的 Pod,且该 Node 必须有一个 Key 为 failure-domain.beta.kubernetes.io/zone 的 标签,即 Node 必须属于 failure-domain.beta.kubernetes.io/zone 拓扑域。
Pod 的反亲和性规则是:这个 Pod 尽量不要调度到这样的 Node,其包含一个 Key 为 kubernetes.io/hostname 的标签,且该 Node 上有标签为 security: S2 的 Pod。
污点与容忍
tains表示给一个node设置一个污点,这样就可以实现普通的POD就不会被调度到这个node上;而toleration表示可以容忍哪些污点,当出现不可使用的node时,就可以调度到出现这个污点的node上。
设置tains
使用 kubectl taint 命令可以给某个 Node 节点设置污点,Node被设置上污点之后就和 Pod 之间存在了一种相斥的关系,可以让 Node 拒绝 Pod 的调度执行,甚至将 Node 已经存在的 Pod 驱逐出去。每个污点的组成如下:key=value:effect。
每个污点有一个 key 和 value 作为污点的标签,其中 value 可以为空,effect 描述污点的作用。当前taint effect支持如下三个选项:
NoSchedule表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上PreferNoSchedule表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上NoExecute表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上,同时会将 Node 上已经存在的 Pod 驱逐出去
NoExecute 可以用在node节点需要维护时,可以把pod全部清理;而PreferNoSchedule可以用在master节点上,当node节点资源不够时,这时pod就可以调度到master上。
设置方法
1 | # 设置污点 |
Tolerations
设置了污点的 Node 将根据 taint 的 effect:NoSchedule、PreferNoSchedule、NoExecute 和 Pod 之间产生 互斥的关系,Pod 将在一定程度上不会被调度到 Node 上。 但我们可以在 Pod 上设置容忍 ( Toleration ) ,意思是设置了容忍的 Pod 将可以容忍污点的存在,可以被调度到存在污点的 Node 上。
1 | tolerations: |
key, vaule, effect 要与 Node 上设置的 taint 保持一致
operator 的值为 Exists 将会忽略 value 值
tolerationSeconds 用于描述当 Pod 需要被驱逐时可以在 Pod 上继续保留运行的时间
当不指定 key 值时,表示容忍所有的污点 key
1
2tolerations:
- operator: "Exists"当不指定 effect 值时,表示容忍所有的污点作用
1
2
3tolerations:
- key: "key"
operator: "Exists"
https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/